Now that we have isolated the data we want to expose in our BI system, we need a process to move it into our BI platform. This process can be implemented using a multitude of different methodologies. I will focus on a couple of them. The three data feeds make up our global source in this example. We need a process to transform the data and a destination for that transformed data.
The process of converting the data into something usable by BI software is called an extracttransform-load (ETL) process. The ETL process has a source and a destination. The data feeds are the source and the data warehouse (which I’ll talk about in detail in the next section) is the destination. The name itself gives away the three main components of an ETL process:
Extract: This refers to the action that performs the extraction of the raw data from
the data feed. For example, for a database, this could be a select statement on a
table. If the data source is an API, this could call a method that extracts all your
contractor names.
Transform: This refers to the action of transforming the data into the required layout in the data warehouse or data mart. This is where the heavy lifting of the ETL process takes place and is usually the part that takes the most time to complete. The data source is rarely in the format that we want for making BI operations easy. Therefore, it is advantageous to perform different types of transforms to prepare the structure of the data in such a way that it can be consumed inside a BI visualization without the need for these complex structural manipulations. Typically, the transform portion of ETL focuses on several main
tasks: vertical partitioning, horizontal partitioning, aggregations, and other less time-consuming tasks like sorting or splitting up tables.
Vertical partitioning refers to filtering the data sets and stripping off unwanted rows from the data. For example, if we had information in our data feed that spanned the years 1950 to 2010 and only the last decade were relevant, we could simply avoid processing the older years to the destination.
Horizontal partitioning is similar to vertical partitioning. However, horizontal partitioning strips off unwanted columns or attributes from the data. For example, if we had address information (city, state, and ZIP) for our consultants in the data feed and this was deemed not relevant to our BI solution, we could simply ignore those columns. The benefit would be that less space would be taken up in our data warehouse.
Aggregation is essentially taking related data for input and returning a single scalar result (e.g., if we wanted to sum up all the hours our consultants worked in a given time period).
Load: This refers to taking the output of the transformation step and placing it into the appropriate location in the data warehouse, which could be a database or an in-memory data structure. The transform step “massages” the data structure so that it will easily fit into the destination tables.
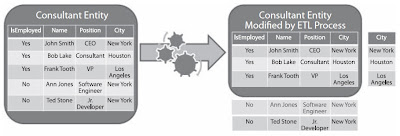 |
http://www.blogger.com/post-edit.g?blogID=889889319149004544&postID=5137629408542511137Click on image to enlarge |
Figure above: Note that the example consultant entity is being horizontally partitioned (by removing the No rows from the IsEmployed column) and vertically partitioned (by removing the City column) before being transferred into the BI data warehouse.
There are many enterprise ETL tools on the market such as SQL Server Integration Services (which is included in SQL Server 2005 and 2008) that provide a visual way of designing, debugging, deploying, and managing data management processes.


